Drown doesn't play sound all night. It stays completely silent and only reacts when noise breaks through. A door slam at 3 AM, a neighbor's bass, a truck outside. Drown masks it instantly, then fades back to silence.
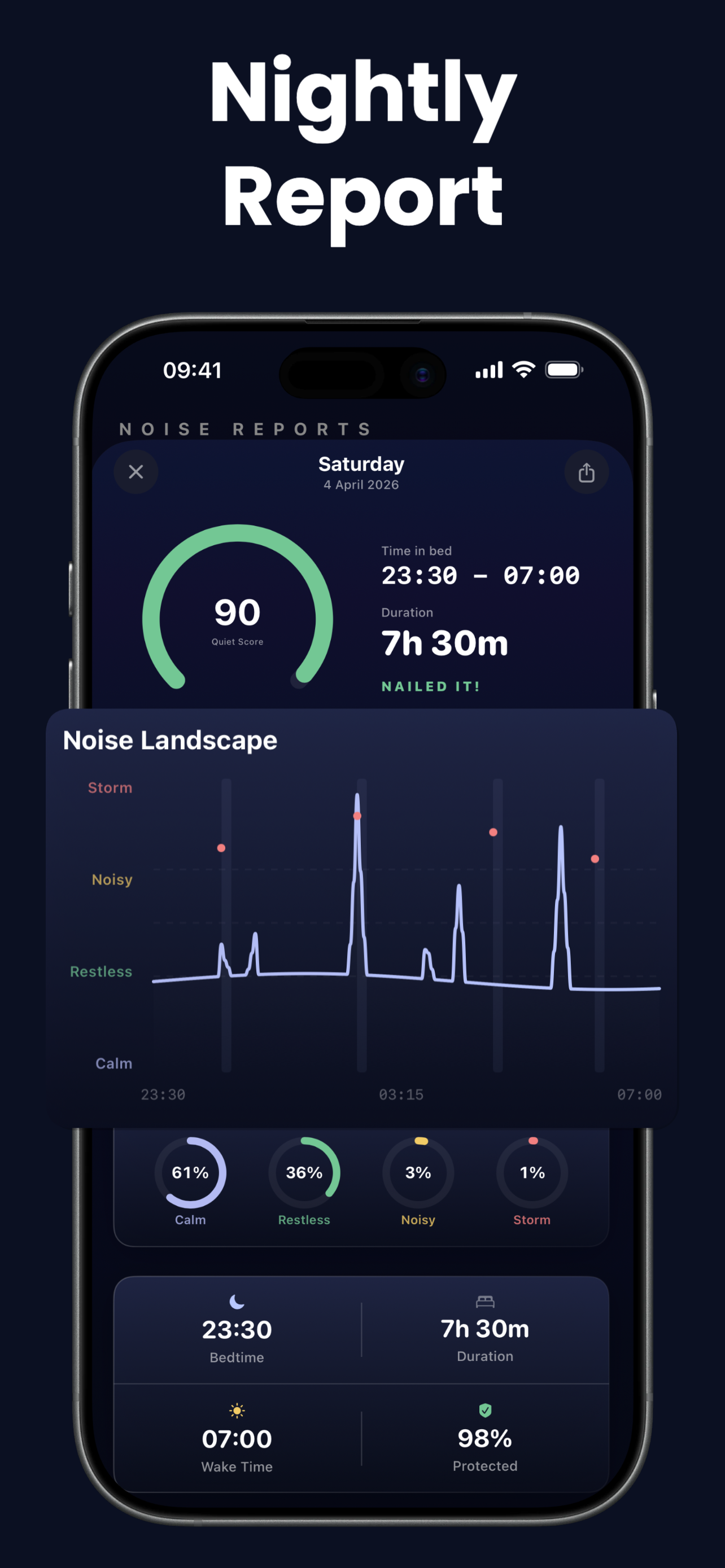
When you tap the shield and close your eyes, Drown calibrates your room in 5 seconds, measuring the ambient noise floor. From that moment on, every sound is compared to that baseline in real time, 44,100 times per second.
If a noise spike exceeds your sensitivity threshold, Drown fades in a masking sound within 200 milliseconds, fast enough that your brain never fully registers the disturbance. When the room goes quiet again, the mask gently fades out over 3 seconds. You stay asleep. The whole cycle takes less time than a single breath.

Most sleep apps play sound all night, brown noise for 8 hours, whether you need it or not. Drown takes the opposite approach. Complete silence is the default. The shield only activates when a genuine noise threat is detected, then gently fades out the moment the disturbance passes.
You get 4 masking sounds to choose from: Brown Noise for deep wall-transmitted rumble like neighbors and footsteps, Pink Noise for voices and TV, White Noise for sharp sounds like sirens, and Rain for light disturbances and snoring.
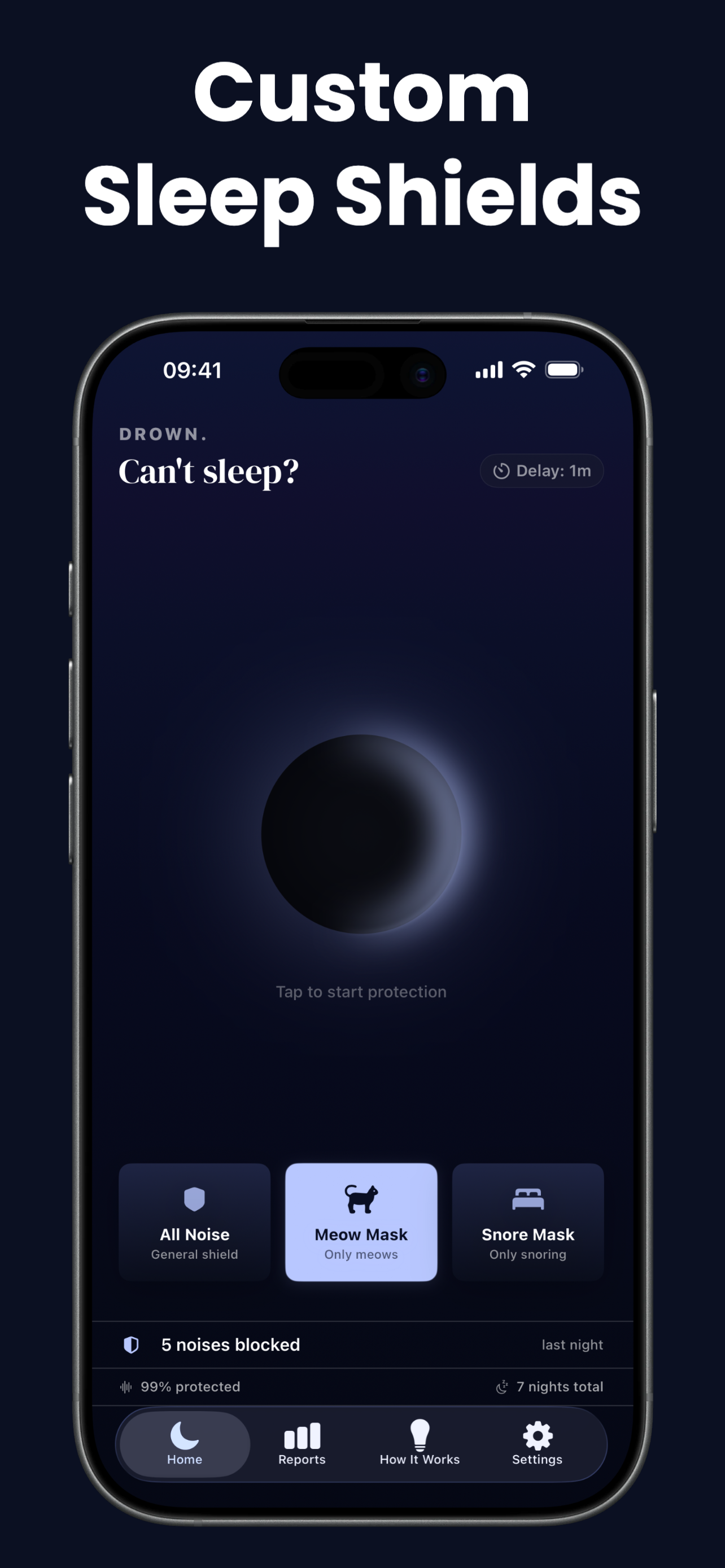
Not all noise is equal. A cat meowing at 4 AM is fundamentally different from a neighbor's bass at midnight. Drown ships with on-device Machine Learning models that can distinguish specific sound types, so the shield only activates for the exact disturbance that wakes you up, ignoring everything else.
General shield that reacts to any sound above your threshold. Uses dual-layer detection: frequency-weighted analysis plus raw volume monitoring. Your breathing won't trigger it, but your neighbor's bass will.
On-device ML model trained specifically on cat vocalizations. All other sounds (doors, neighbors, traffic) are completely ignored. Perfect if your cat is the main sleep disruptor.
Detects snoring patterns from a partner using neural audio classification. Breathing, movement, and environmental noise won't trigger the shield, only rhythmic snoring does.
More smart masks coming as Drown learns what wakes you up.
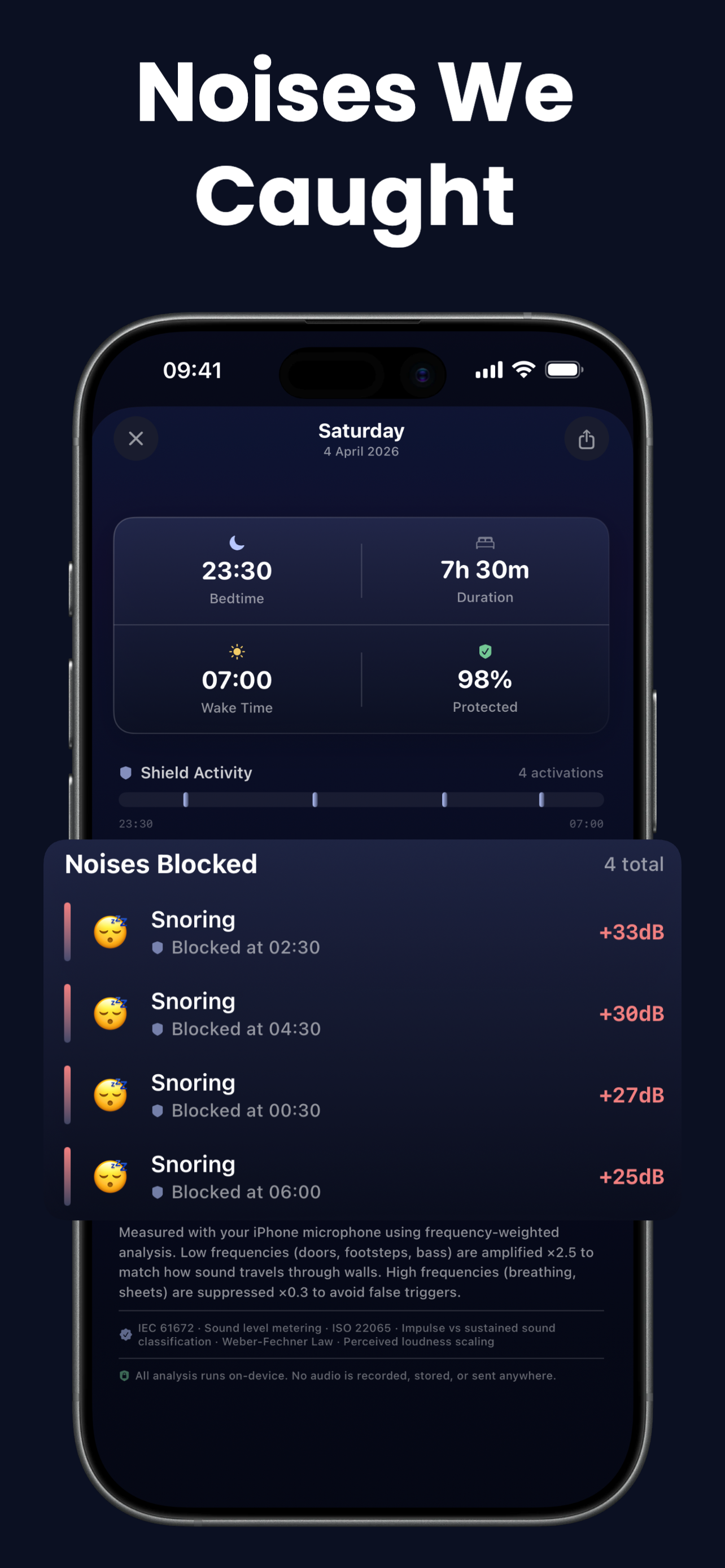
Drown never records, stores, or transmits a single frame of audio. All detection happens on-device using Apple's Core Audio and Accelerate frameworks, processed in volatile memory at 44,100 samples per second, then immediately discarded. No cloud. No account. No analytics trackers. Nothing to delete, because nothing was ever saved.
Free to try. No account. No recording. Works on iPhone.